
What is Apache Kafka?
Apache Kafka is an open-source distributed publish-subscribe messaging platform. It is designed to handle data streams from multiple sources and deliver them to multiple consumers. Kafka operates by maintaining events as records within a cluster of servers, and these servers can span multiple data centers. Kafka is the go-to software for sharing and processing data amongst distributed applications and teams, where high throughput and scalability are the goals.
Installing Apache Kafka on Kubernetes can be quite tasking. All the components have to be deployed separately; the zookeeper alone contains a deployment and a service. By the time all the components are declared, your Kubernetes manifests could be in the dozens. Then the additional task of storing and maintaining the containers for every component is not an easy endeavor.
Finally, making changes to our Kafka cluster and tracking the changes made when there are dozens of manifests can be tedious and lead to many breakages.
Kubernetes Operators are application-specific controllers built by extending the API of Kubernetes. They are tasked with packaging, deploying, and managing applications.
GitOps is a set of practices adopted to manage codified Infrastructure and application configurations using Git as a source of truth.
Between Kubernetes Operators and GitOps, we can simplify the installation and management of our Kafka cluster.
How to install Apache Kafka on Kubernetes with Strimzi
Strimzi is a Kubernetes operator which acts as a dedicated SRE for running Apache Kafka on Kubernetes. It assumes the responsibility of the entire life cycle of Kafka clusters: creating, managing, and monitoring the clusters, and their associated entities (Topics and Users).
By extending the Kubernetes API with Kafka-related custom resource definitions, Strimzi allows us to declare our Kafka components as custom resources. We can describe components such as the number of replicas, the listeners, resource allocation etc., declaratively and Strimzi will ensure that our cluster matches our desired state.
Describing our Kafka cluster for Strimzi
We can describe our Kafka cluster using a YAML file. We can define it using the file detailed below, which you can save as kafka.yaml.
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
version: 3.0.0
replicas: 3
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 100Gi
deleteClaim: false
- id: 1
type: persistent-claim
size: 100Gi
deleteClaim: false
zookeeper:
replicas: 3
storage:
type: persistent-claim
size: 100Gi
deleteClaim: false
entityOperator:
topicOperator: {}
userOperator: {}
Our Kafka Cluster is simple. It contains just three replicas of Kafka brokers making our cluster and three replicas of zookeepers. Other features including types of listeners, MirrorMaker etc., can also be configured.
We can also define our topics using YAML - in this case the below file, topics.yaml.
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: my-topic
labels:
strimzi.io/cluster: apk-cluster
spec:
partitions: 1
replicas: 1
config:
retention.ms: 7200000
segment.bytes: 1073741824
Our Topic includes one partition and the retention time configured
Provisioning our Kubernetes Cluster
Our Kafka Cluster will be installed on Civo.
Civo’s cloud-native infrastructure services are powered by Kubernetes and use the lightweight Kubernetes distribution K3s for superfast launch times.
Prerequisites
To get started, we will need the following:
After setting up the Civo command line with our API key using the instructions in the repository, we can create our cluster using the following command:
civo kubernetes create apk-cluster
our K8s cluster is created:

You will also need to download the KUBECONFIG file for your cluster. The easiest way to do this is to use the CLI again:
civo kubernetes config apk-cluster --save --merge
This should give you output like the following:
Merged with main kubernetes config: ~/.kube/config
Access your cluster with:
kubectl config use-context apk-cluster
kubectl get node
Next, we will install Strimzi in the same namespace as we want our cluster to reside in, using helm.
First, we add the Strimzi repo using this command in our terminal:
helm repo add strimzi https://strimzi.io/charts/
Then we will install it using this command:
helm install strimzi/strimzi-kafka-operator --generate-name
Deploying our applications with GitOps
ArgoCD is a declarative GitOps tool that provides a continuous delivery system for deploying applications on Kubernetes. It uses the GitOps pattern of using Git repositories as the source of truth for defining the desired application state, its environment and configurations. After it is implemented as a custom resource definition, ArgoCD will continuously monitor running applications and compare them with their desired state as specified in a git repository, while taking the required steps to keep them in sync. ArgoCD supports a variety of configuration management tools, including Helm, Kustomize, Ksonnet, Jsonnet, as well as plain YAML/JSON files.
Prerequisites
- Git
- GitHub account
- GitHub CLI
First, we will create the Git repository we want ArgoCD to monitor. This repo will contain our apps and their configuration files.
We can create a GitHub repository with the web console or the command line.
To create a repo from the command line use the following command that uses the GitHub CLI tool gh.
gh repo create
Now that we have our source of truth, aka our git repo, we can install ArgoCD and configure it to start monitoring our repo.
We start by creating a namespace in our cluster:
kubectl create namespace argocd
Then we apply the manifests for ArgoCD to our K8s cluster, into our argocd namespace:
kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
Once all the components of ArgoCD are installed in our cluster, we can use port forwarding to access the API server:
kubectl port-forward svc/argocd-server -n argocd 8080:443
By directing our browser to https://localhost:8080, we can navigate to the ArgoCD web console.
👉🏾 use “admin” as the username to login, and the password can be found as plain text in the “argocd-initial-admin-secret” secret found in ArgoCD installation space. You can find it using
kubectlwith the commandkubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d; echo
Our console, once logged in, should look like this:
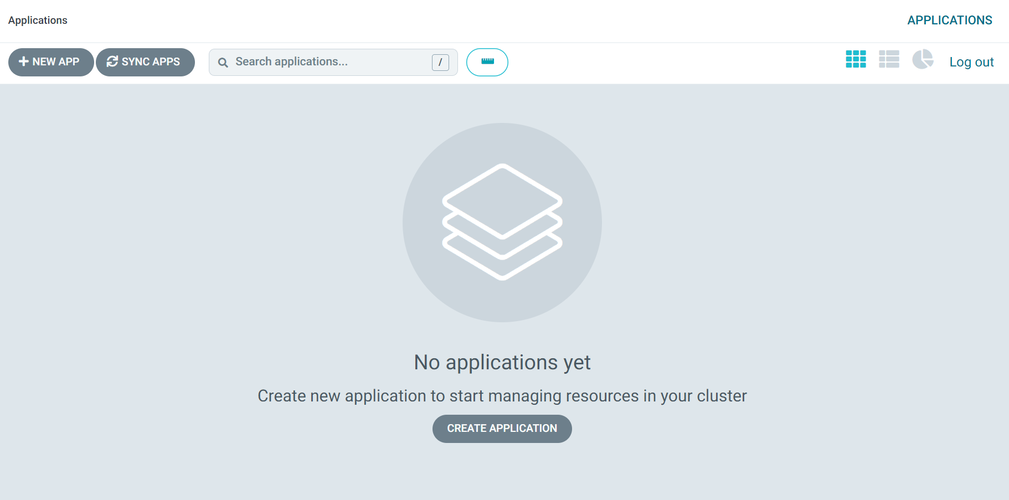
We can interact with ArgoCD through the web console and its command line. To download the ArgoCD CLI tool, you can install it through brew or your operating system's choice of package manager. On a Mac, using brew:
brew install argocd
Finally, we will configure ArgoCD to watch our desired repository by connecting it using HTTPS. This setting can be found under "Settings" on the left hand side, and then "Repositories" on the settings page:
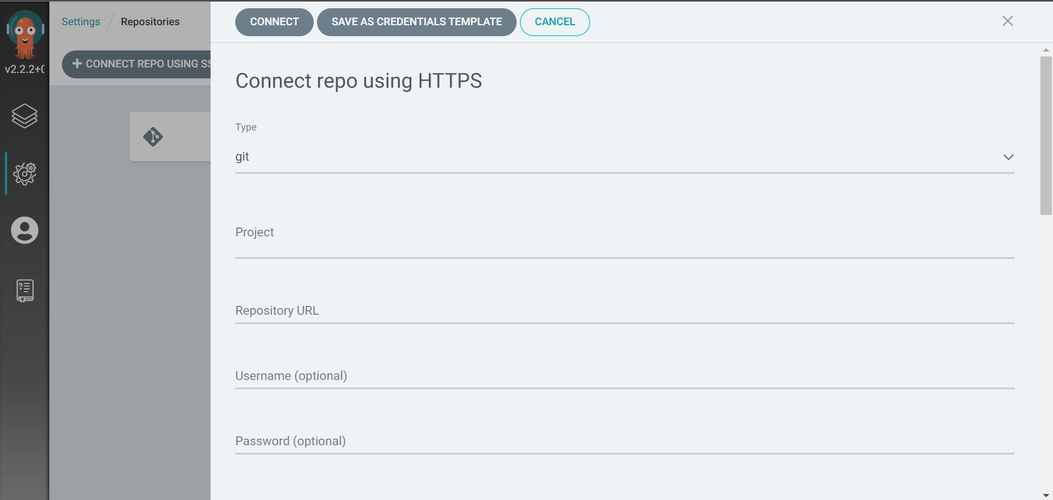
👉🏾 GitHub allows you generate security tokens that can permit apps to take some actions, providing a safer option to using your password. New tokens are generated from the developer settings of our Github profile.
Once you add the URL of the repository you created, our repo is connected and ArgoCD is ready to start monitoring and syncing.
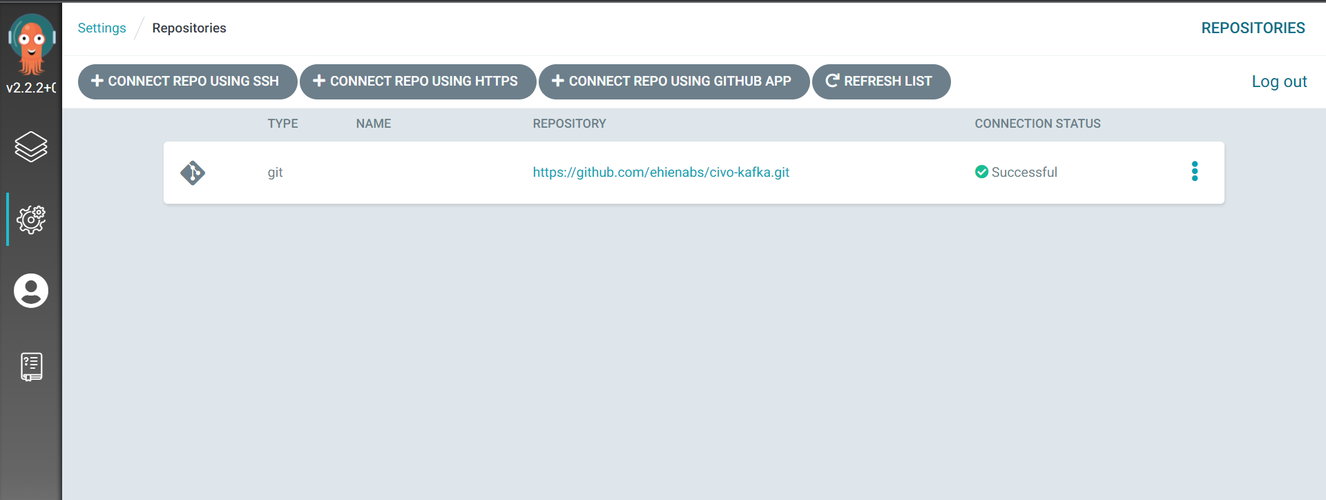
Describing our applications as ArgoCD Apps
An ArgoCD application is a group of Kubernetes resources as defined by a manifest. We can define our application resources, such as the cluster, namespace, repository and directory containing the manifests, sync policy etc., as a deployable unit.
We will define our Kafka cluster as an ArgoCD app in YAML format with the following. Save the yaml code below as a file such as apk-app.yaml, but edit the repoURL to be your Git repository's URL.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: strimziapp
namespace: argocd
spec:
project: default
source:
repoURL: https://github.com/ehienabs/civo-kafka
targetRevision: HEAD
path: apk-cluster/strimzi-apk-cluster
destination:
name: in-cluster
namespace: default
syncPolicy:
automated:
prune: true
selfHeal: true
The above code tells ArgoCD to look in the apk-cluster/strimzi-apk-cluster’ directory of ‘https://github.com/ehienabs/civo-kafka.git’ repository, and sync the desired state, as declared in the Kubernetes manifests, with that of the live state in the Kubernetes cluster. Be sure to replace the repoURL field with your git repository's details.
We can also create an app to manage our Kafka topics with the following. Save the YAML code below as a file, with a name such as topic-app.yaml:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: topicapp
namespace: argocd
spec:
project: default
source:
repoURL: https://github.com/ehienabs/civo-kafka.git
targetRevision: HEAD
path: apk-cluster/topics
destination:
name: in-cluster
namespace: default
syncPolicy:
automated:
prune: true
selfHeal: true
Once again, make sure you change the repoURL field with your git repository's details.
Using Apps of Apps pattern to simplify deployment
The app of apps pattern helps us define a root application. This application rather than watch a directory containing our Kubernetes manifests, watches a directory containing all our apps. It is, effectively, an app containing other apps and greatly simplifies deployment when we are dealing with multiple apps.
Our supervisor app manifest looks like this:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: bigapp
namespace: argocd
spec:
project: default
source:
repoURL: https://github.com/ehienabs/civo-kafka.git
targetRevision: HEAD
path: argocd-apps
destination:
name: in-cluster
namespace: default
Once again, make sure you change the repoURL field with your git repository's details. Save the file as bigapp.yaml
Finally, we install our Kafka cluster and its components by creating our root application. Run kubectl apply against our root app manifest.
kubectl apply -f bigapp.yaml
then push our manifests to our git repo using git:
$ git add bigapp.yaml apk-app.yaml topic-app.yaml
$ git commit -m "add manifest files"
$ git push
ArgoCD immediately detects the changes to our repo and should begin syncing our desired state with the live state of the cluster.

Feels a little like magic installing an apache Kafka cluster using one command, but we can verify that all our components are in our cluster using:
kubectl get pods
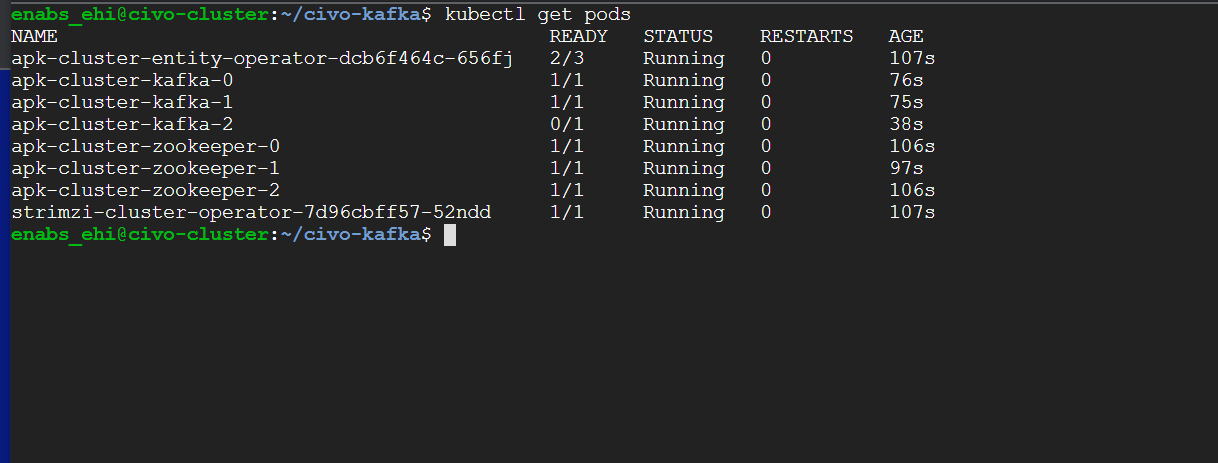
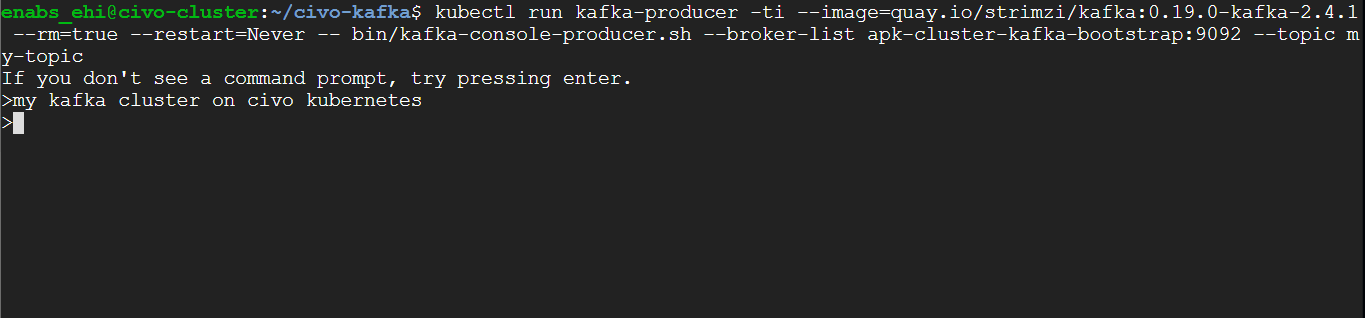
We can also check to make sure our Kafka cluster is sending and receiving messages by first creating a producer using the following command:
kubectl run kafka-producer -ti --image=quay.io/strimzi/kafka:0.19.0-kafka-2.4.1 --rm=true --restart=Never -- bin/kafka-console-producer.sh --broker-list apk-cluster-kafka-bootstrap:9092 --topic my-topic
then we create a consumer in a separate terminal
We can now send messages from our producer terminal:
and we can view them in our consumer terminal:
We can add more messages:
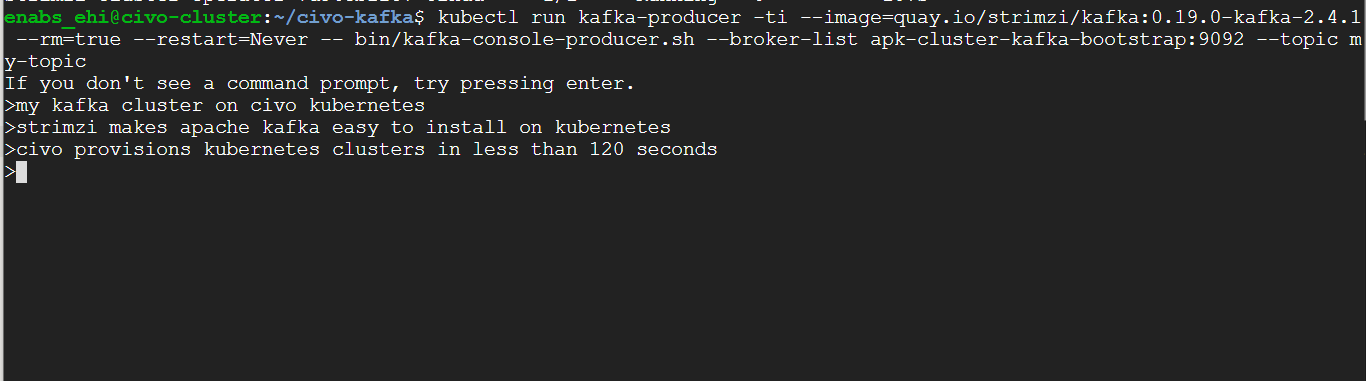
and view them in our consumer terminal:
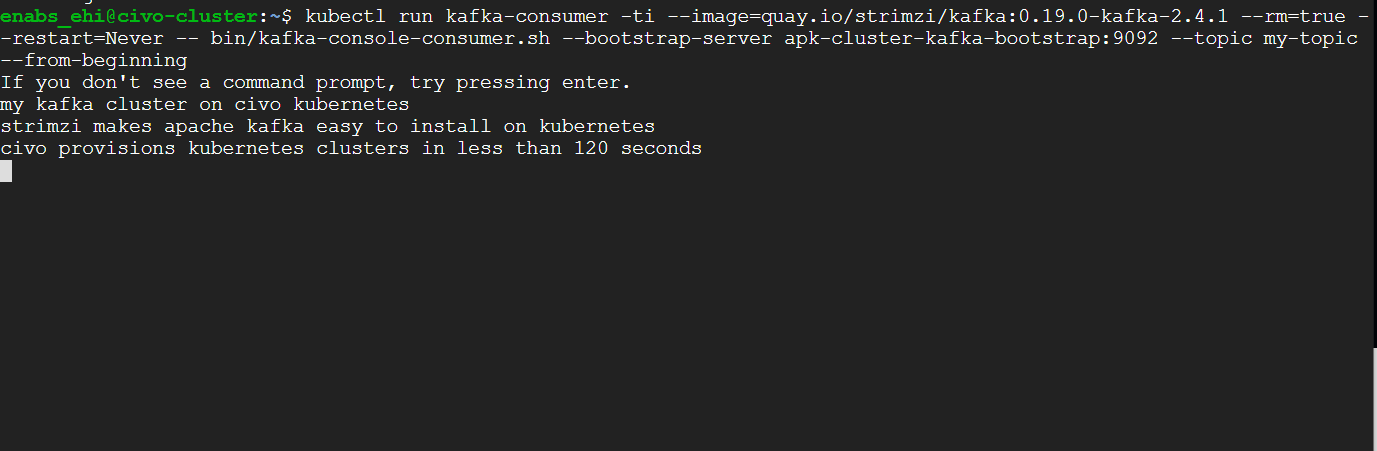
Wrapping up
By following this guide, we will have provisioned a cluster and set up Apache Kafka on it with the help of the Strimzi operator. We also employed ArgoCD to set a GitOps pipeline to manage our application. Once the Kafka cluster was brought online, we demonstrated it works by adding and viewing messages in the stream.
You will be able to clear up the cluster if you so wish by deleting it from the Civo dashboard. This will also stop the ArgoCD deployment from watching for changes in the app specification.
If you followed this guide, let Civo know on Twitter along with how you plan to extend the setup outlined here, or if you have any feedback or corrections!



