Kubernetes is a platform for hosting a bunch of Applications in a highly fault tolerant and scalable way. What this means is that if one of the underlying "nodes" (meaning VMs, servers, computers, etc) stops working, the other nodes in the Kubernetes installation ("cluster") should take over its role and workload.
Containers
Core to Kubernetes is the concept of containers. This has been made popular recently by Docker, but if you aren't aware of what it means - basically a container is a self-contained filesystem and instructions on a single process that should be started. This may be your application code with a Dockerfile that describes how to launch your application, or it may be a database that will listen for incoming connections and handle SQL (or noSQL or key/value) data.
Why Kubernetes
How to make a container of your application is outside the scope of this document, but let's assume for now that you've managed that (maybe you're working locally with Docker). You now want to get it up and running on the big, bad Internet! You could just launch a VM somewhere (Civo would be a good choice ?) and install Docker and then launch that container on there. But then what happens if Docker crashes on that VM? Or if the VM itself dies? Your application is down.
So you need some way of ensuring, given multiple VMs that your application has the best chance of always being up and running.
Or maybe your application has gotten really successful and you need to "scale it" (make it handle more and more customers). You could launch more Docker containers on that single VM (putting even more eggs in your one basket) or launch more VMs and put one or more containers on each. However, that then becomes a manual process of launching the extra containers. And what happens when you're ready to release version 1.1 of your application? That's right, go round each VM, shut the containers down and launch new ones.
How Kubernetes can help
The idea of Kubernetes is that it's an "orchestration" platform - it sits there and manages the moving of your containers between nodes, launching more when necessary, handling rolling deploys of updates as well as providing load balancing between the containers.
However, in order get all of this modern cloud-native goodness, you need to be familiar with Kubernetes core concepts and how they interact together.
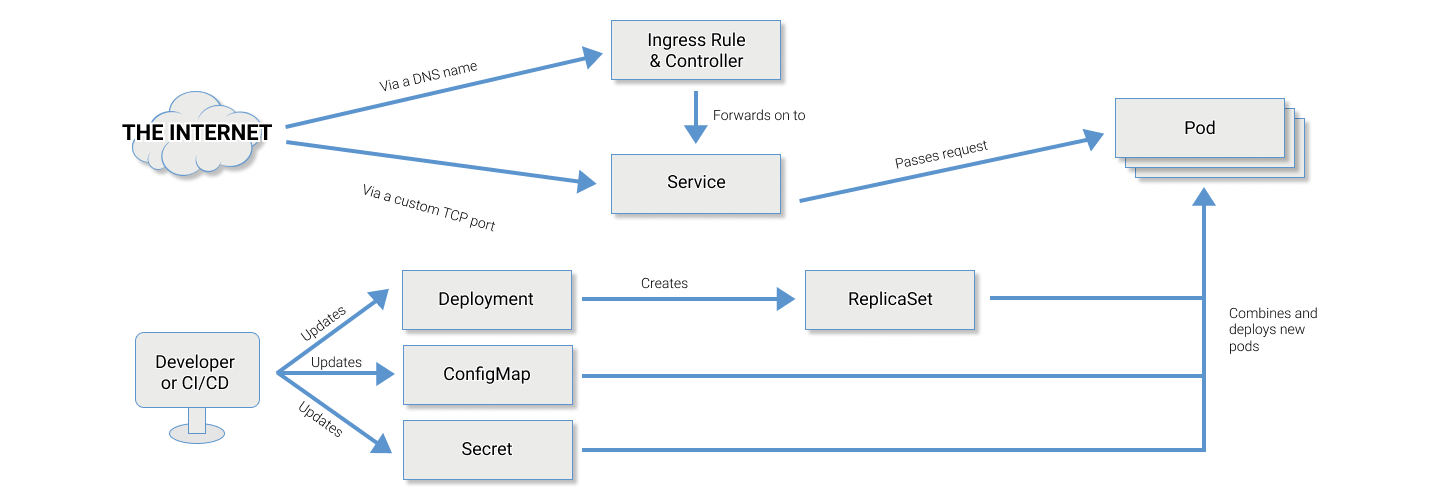
Pods
A pod is a group of one or more containers. For a lot of applications this may just be a single container per pod, but you may also choose to have a database or proxy deployed alongside your container, one for every application container.
Each pod has an IP address on your Kubernetes internal network.
ReplicaSets
A replica set is a set of rules used by Kubernetes to tell it how many pods it should run. You can choose to scale a replica set at any time to use more or less of your capacity (ideally supporting more or fewer customers).
Services
So you have a bunch of pods running across some nodes and now a customer connects and something needs to know which nodes are running your application and on which IP addresses/ports. A service links your pods to a single port that is available from all nodes. If you wanted, you could run a load balancer such as haproxy outside your Kubernetes and connect to that single port, load balancing between all of your nodes. Regardless of whether a node connected to is running a pod or not, it will accept the network request and forward it on.
Ingress
Of course, it's better to run this load balancing capability inside of Kubernetes. You can run an "Ingress Controller" inside Kubernetes, such as Traefik, haproxy or nginx. Then configure "Ingress Rules" that declare to the Ingress Controller that for a given application (DNS domain name, port, TLS/SSL/etc) which service it should connect to.
Deployments
So if you have your code (all built into a Docker container) and running through a ReplicaSet on multiple pods, what happens when you want to run Version+1? You use a Deployment to manage the ReplicaSets, and this will take care of rolling out the update one pod at a time (and making sure it's responding with a healthy status), shutting down one old version pod each time the new ones become available.
ConfigMaps
Your application in production will need different configuration from the version running on your development machine. For example, the database hostname will be different, likely the database name itself will be different, maybe a payment provider will require a different token for integration.
A ConfigMap is a set of configuration values. You can either make these available as ENVironment variables passed into your application or in a volume mounted at a particular place at the filesystem that your application can read (a VolumeMount).
Secrets
Secrets are made available to the environment in the same way as ConfigMap settings are but each is a single secret and these are stored encrypted in Kubernetes. So for example, your database authentication credentials are best stored in Secrets rather than just put in plain text in a ConfigMap.
Horizontal Pod Autoscaler
You can launch another container that will monitor each of your pods and if their CPU hits a certain threshold it will automatically scale your ReplicaSet up (to a configured maximum). It will also scale them back down if the CPU is below the configured value, checking every 5 minutes (by default).
Jobs
You can launch one-off processes to run for your application. These can be created at any time, but one common use case is for database upgrades during deployment. Closely related is a CronJob which launches multiple Jobs on a specified schedule.



