
Prometheus PushGateway is a very useful tool to visualize batch metrics which will allow us to pull IOT (Internet of Things) sensor data into Prometheus. This tutorial will walk through setting up a PushGateway instance and logging metrics from a simple BASH script. This is a great way to quickly visualize data external to Kubernetes in a simple, sysadmin-friendly way.
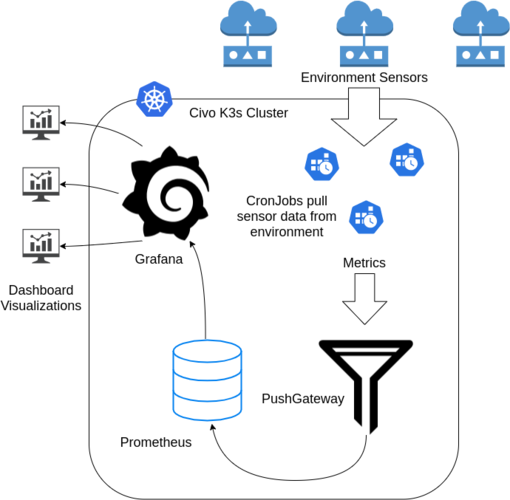
This tutorial outlines how Prometheus PushGateway can be set up on top of Civo's K3s offering. Through this, we will then push some data to the gateway and visualize it in Grafana. By the end of this, we aim to create an environmental monitoring system that gathers sensor data. I won't actually deploy the scrape jobs in this tutorial, but we will send a metric with curl and visualize it in each of the core components.
Pre-requisites
Before we get sarted with this tutorial, you should ensure that the following items are in place:
K3s ships with a Helm operator that takes a Custom Resource Definition (CRD) which can be applied with kubectl. This tutorial will deploy Grafana and PushGateway using this method. More information can be found here
Setup
Before getting started let's export some variables so they will be available throughout this tutorial. We also want to update our Helm repo with the latest charts:
export CLUSTER_NAME=civo-iot-$(whoami)
export NAMESPACE=default
Provisioning your cluster
The first step is to provision a K3s cluster using the Civo CLI.
This will take a couple of minutes, once finished the --save flag will point your Kubectl context to the new cluster. The command is:
$ civo kubernetes create \
--applications prometheus-operator \
--nodes 2 \ --save --switch --wait \
${CLUSTER_NAME}
We are initializing the cluster with the prometheus-operator application from the Civo Marketplace.
Now we will install prometheus-operator via Helm chart into monitoring namespace in the newly created cluster as follows:
Step 1: Creating the monitoring namespace in the cluster with Kubectl:
$ kubectl create namespace monitoring
Step 2: Add the Helm repo:
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm repo update
Step 3: Install it into the monitoring namespace:
$ helm install prometheus prometheus-community/kube-prometheus-stack --namespace monitoring
Once Helm has finished installing you can explore the default cluster monitors, provisioned by the Prometheus helm chart. First port-forward to the Grafana instance: kubectl port-forward svc/prometheus-grafana 8080:80 --namespace monitoring and navigate to http://localhost:8080 . You can log in with the username admin and the password prom-operator.
If you click around, you may find that not every dashboard will work, since the K3s distribution has a slightly different topology than a vanilla Kubernetes cluster.
In the next steps, we will provision our own instances of Prometheus and Grafana.
Deploying core applications
The stack consists of a few core applications, and jobs to fetch the data:
- Grafana: is a powerful visualization tool we will use for displaying our metrics. This could be considered the 'frontend' of our application.
- Prometheus: is a time-series database that scales incredibly well. This is our 'backend'. Prometheus is generally configured to scrape metrics data from applications on regular intervals.
- PushGateway: is a 'sink' or 'buffer' for metric data that is too short lived for Prometheus to scrape. This is what our
cronjobs will log data to since the containers won't live long enough for Prometheus to ever see them.
Installing Grafana
To deploy Grafana, we just need to create a deployment and apply it to our cluster.
# deploy/charts/grafana.yaml
#
cat < /tmp/grafana.yaml
apiVersion: helm.cattle.io/v1
kind: HelmChart
metadata:
name: grafana
namespace: kube-system
spec:
repo: https://grafana.github.io/helm-charts
chart: grafana
version: 6.58.6
targetNamespace: default
valuesContent: |-
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
url: http://prometheus-operated:9090
access: proxy
isDefault: true
EOF
# Apply the chart
kubectl apply -f /tmp/grafana.yaml
Link to GitHub Gist: https://gist.github.com/narenarjun/8a5e5785e76c4cc47f736598c4dbc742#file-grafana-yaml
Installing Prometheus
When we provisioned the cluster we installed the prometheus operator which installs an instance of prometheus by default. This instance is used for monitoring the cluster so we generally want to avoid using it for application data. Luckily operators make it super easy to spawn new instances. We simply need to create a Prometheus CRD and attach some RBAC permissions.]
This is required yaml file:
cat /tmp/prometheus.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: default
---
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
Labels:
app: prometheus
name: prometheus
spec:
serviceAccountName: prometheus
serviceMonitorSelector:
matchLabels:
app: prometheus-pushgateway
EOF
# Apply the yaml file:
$ kubectl apply -n ${NAMESPACE} -f /tmp/prometheus.yam
Link to GitHub Gist: https://gist.github.com/narenarjun/8a5e5785e76c4cc47f736598c4dbc742#file-prometheus-yaml
Installing Push-Gateway
apiVersion: helm.cattle.io/v1
kind: HelmChart
metadata:
name: metrics-sink
namespace: kube-system
spec:
repo: https://prometheus-community.github.io/helm-charts
chart: prometheus-pushgateway
version: 2.4.0
targetNamespace: default
valuesContent: |-
metrics:
enabled: true
serviceMonitor:
enabled: true
namespace: default
additionalLabels:
app: prometheus-pushgateway
Link to GitHub Gist: https://gist.github.com/narenarjun/8a5e5785e76c4cc47f736598c4dbc742#file-pushgateway-yaml
Visualizing data
Lets validate that the services are all working by pushing a data point to PushGateway manually.
Wait until all pods are running and then start the proxies:
# Proxy Grafana
kubectl port-forward svc/grafana -n ${NAMESPACE} 8080:80 &
# Proxy Prometheus
kubectl port-forward svc/prometheus-operated -n ${NAMESPACE} 9090:9090 &
# Proxy PushGateway
kubectl port-forward svc/metrics-sink-prometheus-pushgateway -n ${NAMESPACE} 9091:9091 &
Once the proxies are active you can drop a metric onto the pushgateway:
$ echo "sample_metric 1" | curl --silent --data-binary @- "http://localhost:9091/metrics/job/sanity-test"
$ echo "sample_metric 200" | curl --silent --data-binary @- "http://localhost:9091/metrics/job/sanity-test"
$ echo "sample_metric 1" | curl --silent --data-binary @- "http://localhost:9091/metrics/job/sanity-test"
$ echo "sample_metric 1000" | curl --silent --data-binary @- "http://localhost:9091/metrics/job/sanity-test"
$ echo "sample_metric 1" | curl --silent --data-binary @- "http://localhost:9091/metrics/job/sanity-test"
Note: these are made up sample values to see a minimal graph in the visual
Visualizing in PushGateway
Navigate your browser to http://localhost:9091.
Notice there is a new group for sanity-test and the data point sample_metric is equal to 1.
Note: the PushGateway will show us the last value we sent to it, which as 1 as per the last execution. You can change it to different values and refresh the page to see it reflected

To see the raw metrics that prometheus will scrape, navigate to http://localhost:9091/metrics and notice the new line at the bottom:
# TYPE sample_metric untyped
sample_metric{instance="",job="sanity-test"} 1
Visualizing in Prometheus
You can see Prometheus deployed at http://localhost:9090.
Prometheus is where the data will be aggregated and we can perform queries over time. Since we only have a single data point we will see a line in the graph when searching for sample_metric. As we build out the monitoring system we can add CRDs to generate alerts on our data.

Visualizing in Grafana
Grafana is where we will compile dashboards to display Prometheus queries.
To get the password for the next step run: kubectl get secret --namespace default grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
You will be able to log in with the username admin and your password from the previous step. Again the visualization is not very interesting with a single data point, but this is a simple sanity test.
To validate our sample metric we are going to use the Explore function. Navigate to http://localhost:8080/explore

Wrapping up
Congratulations! You now have the foundation for a batch metrics monitoring system! Keep an eye out for the next post where I will walk through connecting real sensor data.



