
As a cloud provider and DevOps-focused company, we definitely want to practice what we preach. We see the benefits of a modern cloud native architecture, so we built our hosting of www.civo.com and civo.com/api (our application) to take full use of these modern decisions.
This post describes our approach to Continuous Integration (CI) and Continuous Deployment (CD) from a Chief Technical Officer's perspective. Continuous Integration refers to developers merging their code to a branch several times throughout a development phase, while Continuous Deployment is the practice of deploying code to production as soon as it passes a set of automated tests.
Testing
The first step in building any modern application is in repeatable automated testing. We need to be able to quickly and easily ensure our application (both the site and the API) is still working.
As a Rails shop the two main choices for automated testing are Rails' default MiniTest or the community favourite RSpec; with us having more experience as a company with RSpec, that's the one we went for. To be honest, compared to previous experiences with other languages, either is a dream - but we went with the one that feels like it reads more naturally.
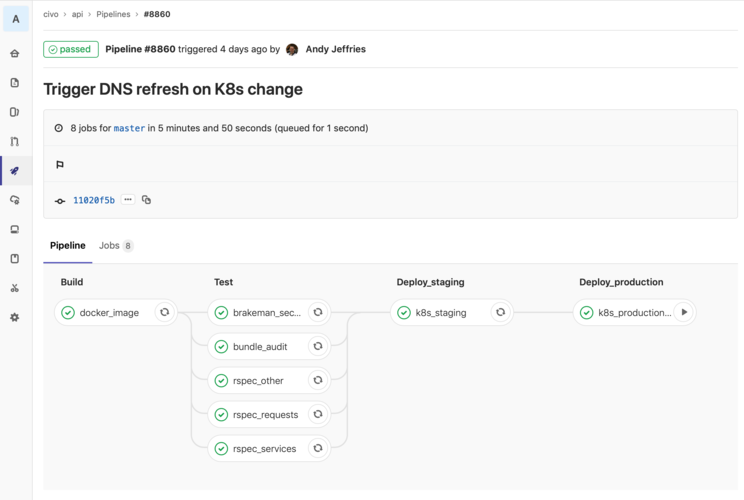
So we have a suite of tests for both WWW and API, these are run locally on developers machines (of course) but also on every git push we run the tests using a self-host GitLab instance and a handful of GitLab Runners - all hosted on Civo.com itself (we dogfood our own platform always).
Security
There are two gems we use for automated security checking of our application:
- bundler-audit which checks for known security vulnerabilities in our list of Ruby gems used in our projects
- Brakeman which uses static analysis to try to determine if there are security flaws in our Ruby code
Neither of these replace a keen eye for security problems as the code is written and following best practices (such as not concatenating strings to be executed against a SQL database), but they're a useful line of defence.
Master/branches
Our feature work (i.e. more than a single commit, longer than half a day) is done on branches by developers, who then raise a Merge Request (GitLab's equivalent to a Pull Request). We make single commit bug fixes directly on master.
Most of our developers' work is just merged to master when it's ready for deployment. New developers or Junior developers will have their code reviewed by a senior developer or the CTO before being merged in.
Staging and production
We have a single multi-master, separate etcd Kubernetes cluster running on Civo.com which hosts our application. It has different namespaces for staging and production, so the applications for different environments are isolated there.
The basic process for deployment of both components of our application are (although the order can vary between projects):
- Run RSpec tests (often split into multiple jobs for different sets of tests, so they can be run in parallel on different workers)
- Check for security issues in the Gem list or code (as described above)
- Build a Docker image of the component (we have a Learn Guide on dockerizing a Rails app
- Push the Docker image to GitLab's own internal Container Registry which is self-hosted and requires authentication
- Using a bunch of template YAML files, insert some specific values from this build (e.g. the pipeline number from GitLab) and apply those YAML files to our Kubernetes cluster in the staging namespace
After we've given it a run-through on our staging environment, we can then with a single click deploy it to production.
We also have some flags for our commit messages that can skip automated testing (we'll have ran it locally anyway) and deploy straight to production - but these are used for "the world is broken" fixes only. We agree with the philosophy from 2014 (before they changed it to refer to stable infrastructure):
Move fast and break things -- Facebook
We don't see that as allowing sloppy code, just that developers have to work without fear of innovating and too much worry about breaking things causes developers to not innovate quickly enough through fear.
Kubernetes does an automatic rolling deploy when you update the image tag of a deployment, so this automatically achieves the holy grail of zero-downtime deployments. Indeed we often deploy 10-15 times per day and yes, we're one of those companies that does Friday deploys (even an hour before we leave the office).

If you don't have confidence in your product, maybe you shouldn't do Friday deploys - or maybe the fact you don't have confidence is the problem, not the Friday deploys and you should fix that by adding more/better tests!
Taking it one nice step further
So we've talked about staging and production, but there's one nice little step we do which is something lots of people would love to have. Imagine the scenario: A developer and designer have been working on a feature branch for a couple of weeks, it's ready to go but everyone wants one last chance to review it over the weekend and give final feedback.
Do you:
- merge it to master, think "just ship it" and revert the merge if you need to fix production or push out some other urgent feature?
- show it everyone on your developer machine?
- something else?
We go with option 3! Our feature branches are deployed within a single Kubernetes namespace but using a hostname with the name of the branch in it. Later these feature branch deployments are reaped when the branch no longer exists - maybe it was merged to master or maybe it was an experiment and deleted.
How you can do it too
So all of this is achievable on Civo, we've proved it because we self-host and do it all ourselves. So why not sign up for a Civo account and give it a try? If you need help figuring anything out, get in touch and we can help you with the steps. Maybe you could even publish a Learn Guide on our site to help others afterwards?
